
Published: 22 April 2026
Mining operations generate enormous volumes of data every shift. But when it comes to maintenance, the mines best positioned for the future aren't necessarily the ones with the most sophisticated tools today. They're the ones collecting the right data now.
Every maintenance professional in mining understands the goal: maximize equipment availability so the operation can move more material with the fleet it already has. Nobody wants to buy a truck they don't need. Shop time isn't the enemy here. Planned maintenance keeps equipment healthy. The real enemy is unplanned downtime.
A haul truck that throws a fault halfway up a ramp doesn't just stop hauling. It blocks a route. It might need a tow. Replacement parts get rush-ordered at a premium. And while your maintenance crew scrambles to deal with the emergency, the planned work on other units gets pushed back, creating a ripple effect across the entire fleet. Planned maintenance is disruptive enough on its own. Unplanned maintenance is where the real cost hides.
The Maintenance Maturity Ladder
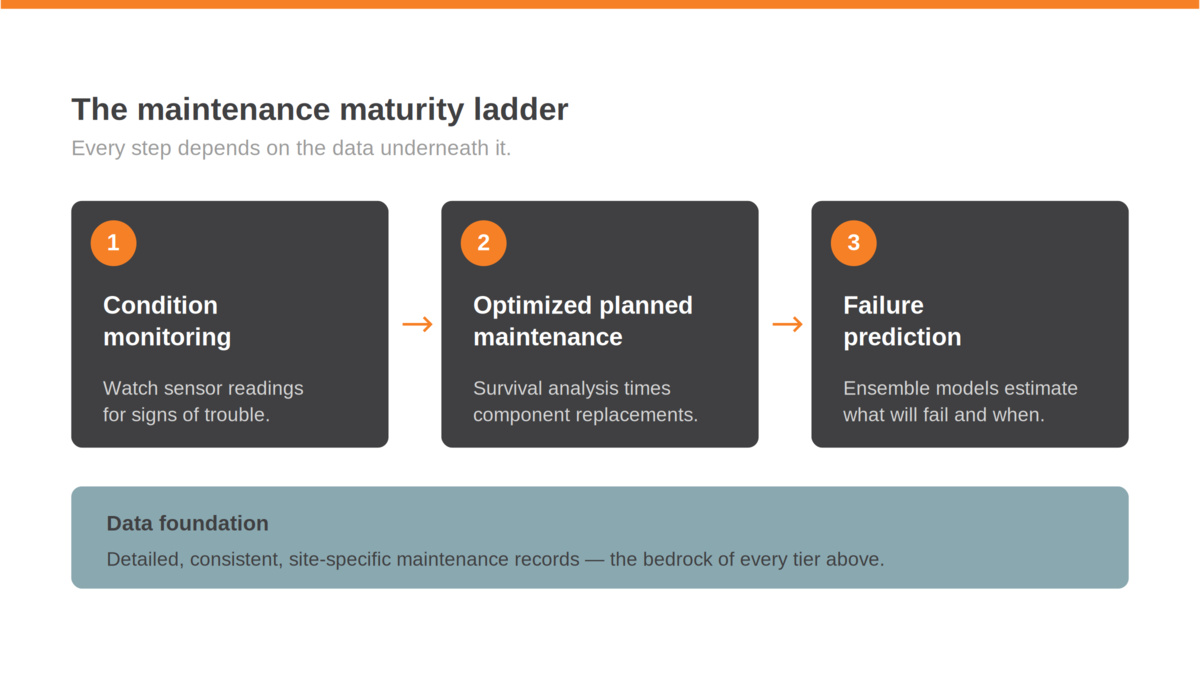
Most mines are somewhere on a progression that looks roughly like this.
Condition monitoring is the foundation. You instrument your fleet, pull data from OEM sensors, and watch for signs that something is going wrong. When a temperature or pressure reading trends in the wrong direction, you catch it before it turns into a roadside breakdown. This is valuable work, and it's where a lot of operations are focused today.
The next step up is optimized planned maintenance scheduling. Preventive maintenance, the routine stuff like oil and filter changes, is largely dictated by OEM guidelines and often tied to warranty requirements. There's not a lot of room to optimize there. But planned component replacements are a different story. This is where you stop replacing major components purely based on OEM-recommended intervals and start using statistical models to find the point that actually minimizes your total cost of ownership. The idea is straightforward: replace a component too early and you're wasting remaining useful life. Wait too long and you're paying for unplanned failures. Somewhere in between is a sweet spot.
The tool for finding that sweet spot is a survival analysis model, or a Weibull curve as it's commonly known in reliability circles. It takes historical failure data for a given component and helps you identify the interval where the cost of a planned replacement balances against the cost and probability of an unplanned failure. But there's an element of art to it. The math gives you a starting point, and from there, the parameters need to be tuned for your specific operation. That's typically where vendor expertise comes in. Experienced reliability specialists who've worked across multiple sites can dial in the model faster than starting from scratch, and refine it over time as more data comes in.
Then there's the next frontier: failure prediction. This is the one that gets the most attention at conferences and in vendor pitch decks, but it's worth being precise about what we mean, because the term gets used loosely.
A lot of what's currently marketed as "AI-powered failure prediction" is actually anomaly detection. Anomaly detection is valuable. It's essentially a step up from condition-based monitoring: instead of watching for a single parameter to cross a threshold, it learns what "normal" looks like across multiple variables and flags when something deviates. The limitation is that it can tell you something is wrong, but not necessarily what is wrong or when a failure will occur. Your team still needs to diagnose the issue, which means you're reacting faster, but you're still reacting.
True failure prediction is more ambitious. It's not a single model but a combination of approaches working together: anomaly detection to spot deviations, classification models to identify what is likely failing, remaining useful life (RUL) estimation to predict when, and accelerated failure time (AFT) models to account for operating conditions. The end result is a system that can tell you when a specific component on a specific truck is likely to fail, based on how it's actually being used. That lets you push components beyond the statistical optimum from your Weibull analysis, right up to the edge of their useful life, squeezing the maximum value out of every dollar you spend on parts and labour.
These prediction systems rely on machine learning, and that means they need training data. Lots of it. And because they combine multiple model types, they need multiple kinds of data: sensor readings, failure records, repair logs, operating context.
The Common Thread Is Data
Here's where all three levels of maintenance maturity converge. Condition monitoring needs sensor data. Weibull-based planned maintenance optimization needs historical records of component failures, mean time between failures (MTBF), and mean time to repair (MTTR) for both planned and unplanned events. And true prediction, because it combines multiple model types, is the most data-hungry of all. It needs sensor data, failure histories, and repair logs, but it also needs enough volume and variety to train each model in the ensemble. Anomaly detection needs to learn what "normal" looks like for each component under different operating conditions. Classification models need labelled failure modes. RUL models need run-to-failure histories. The richer and more detailed your records, the more capable these tools become.
Industry-average data can get you started, but it's not a lot better than following OEM guidance. The data that actually moves the needle is your data, from your equipment, operating in your conditions. A haul truck working a steep, hot pit in the Pilbara wears differently than the same model running flat hauls in northern Canada. Generic benchmarks can't capture that.
So whether you're building toward optimized planned maintenance scheduling or laying the groundwork for predictive tools, the prerequisite is the same: detailed, consistent, site-specific maintenance records.
What "Good Data" Actually Means
This isn't just about recording that a truck went down and came back up. The value is in the detail.
You need to know what caused the downtime. You need to track every action taken during a repair, how long each step took, and what parts were involved. You need that information reconciled against a reliable time model so your records reflect reality. If your maintenance log says a truck was down for six hours but your shift records can't account for when those hours occurred, the data loses its value fast.
This is where tools like Maintenance Monitor become important. Because it's tightly integrated with the Wencomine fleet management system, every maintenance event is tracked against the same time model that governs the rest of the operation. Statuses are reconciled. There's no ambiguity about when a unit went down, what happened while it was down, and when it came back online.
On the sensor side, ReadyLine captures real-time health data from OEM sensors on your equipment, including alarms and fault codes. It also lets you configure virtual sensors and virtual alarms, which means you can define your own monitoring thresholds based on what matters to your operation, not just what the OEM ships by default.
Together, these systems capture exactly the types of data that planned maintenance optimization and prediction tools need as inputs: detailed downtime records, component-level failure histories, repair durations, and real-time equipment health signals.
The Investment You Make Now Pays Off Later
Good versions of planned maintenance optimization and failure prediction tools are not some distant fantasy. Modest versions exist today, and the technology is maturing quickly. But even the best model is only as good as the data behind it.
If your mine isn't capturing detailed maintenance records and equipment health data today, those tools won't have much to work with when you're ready to adopt them. You'll be starting from scratch while other operations, the ones that invested in data collection early, are already tuning their models and seeing results.
We're building toward a more comprehensive set of maintenance and asset health tools at Wenco, and data quality is the foundation everything else sits on. The mines that will benefit the most are the ones that start treating data collection as a strategic investment rather than an administrative task.
The next generation of maintenance isn't about a single breakthrough technology. It's about having the data in place to make those technologies work.
Want to learn more about how Wenco's maintenance solutions can help your operation build a stronger data foundation? Get in touch.
Published: 22 April 2026
Last Updated: 22 April 2026